cse15l-lab-reports
Lab Report 2 - Week 4
Debugging Code
This week’s report goes through the process of how to debug code and identifying the different aspects of a bug, such as failure-inducing input, bugs, and symptoms. I go through some symptoms I observed when running the code and how I approach fixing the issues.
The code I use in this report is MarkdownParse, which is a Java class containing a function that is meant to extract the url of links in markdown files. While the function works on certain test cases, there are many issues with the code that this report seeks to find and fix. The original repository for MarkdownParse can be found on ucsd-cse15l-w22’s GitHub account. The link to the markdown parse repo can be found here: markdown-parse repo.
Expected Behavior
The MarkdownParse function is expected to parse a markdown file and extract the url of any embedded links. The idea is to use the locations of the brackets, “[” and “]”, and the locations of the following parenthesis, “(“ and “)”, to find where links might be located. In markdown, the text users would see on the webpage would be contained in the brackets, whereas the actual urls the links lead to are contained within the parenthesis.
Below is the original starting code that can be found in the markdown-parse repo that declares and defines the getLinks function.
// File reading code from https://howtodoinjava.com/java/io/java-read-file-to-string-examples/
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.util.ArrayList;
public class MarkdownParse {
public static ArrayList<String> getLinks(String markdown) {
ArrayList<String> toReturn = new ArrayList<>();
// find the next [, then find the ], then find the (, then take up to
// the next )
int currentIndex = 0;
while(currentIndex < markdown.length()) {
int nextOpenBracket = markdown.indexOf("[", currentIndex);
int nextCloseBracket = markdown.indexOf("]", nextOpenBracket);
int openParen = markdown.indexOf("(", nextCloseBracket);
int closeParen = markdown.indexOf(")", openParen);
toReturn.add(markdown.substring(openParen + 1, closeParen));
currentIndex = closeParen + 1;
}
return toReturn;
}
public static void main(String[] args) throws IOException {
Path fileName = Path.of(args[0]);
String contents = Files.readString(fileName);
ArrayList<String> links = getLinks(contents);
System.out.println(links);
}
}
Source: ucsd-cse15l-w22’s MarkdownParse repository
The original function is able to do this in certain test cases, such as when there are valid markdown links with no other text following it. Here is an example of a test case that works and the correct output.
<!-- Working Test Case, test-file.md -->
# Title
[a link!](https://something.com)
[another link!](some-page.html)
The expected output of the above markdown file should be a list containing the two links seen inside the parenthesis.
<!-- Expected Output -->
[https://something.com, some-page.html]
The following is a screenshot of compiling and running the program on the test-file.md markdown file.

As we can see from the results above, the output matches what we expected to get. However, this is not the case for all markdown files. The following cases show examples of how the code does not cover all test cases and can actually break the code or returns an unexpected output.
Case 1: Images in markdown
One test case that I found that led to an unexpected output was if we add images to the markdown file. Images are added in a very similar style as links, except that an image begins with an exclamation mark (!), such that images would be embedded in the following format: . However, the file path used in the image is not a desired output we want to include when we extract links, which is what happened when we ran the original function on files containing markdown images.
The following markdown file is a test that contained a markdown image which was the failure-inducing input. Link to markdown file

Using the original getLinks function on the failure-inducing input, we get the following output.

In the output, we get a list containing the image path we used to embed the image in markdown. However, the getLinks function is not meant to extract image links. The additional filepath that was returned with the output is the symptom of a bug that results in the unexpected output.
In order to deal with this symptom, I determined that the bug in our code came from a lack of differentiating between images and links in markdown. To determine whether the code was checking an image or a link, I added a check for exclamation points that came before the opening bracket, which indicated that the following was an image. If the code finds an exclamation point followed by a markdown link formatting, then it will skip to the next bracket since we want to avoid images. Changes to function to avoid including images
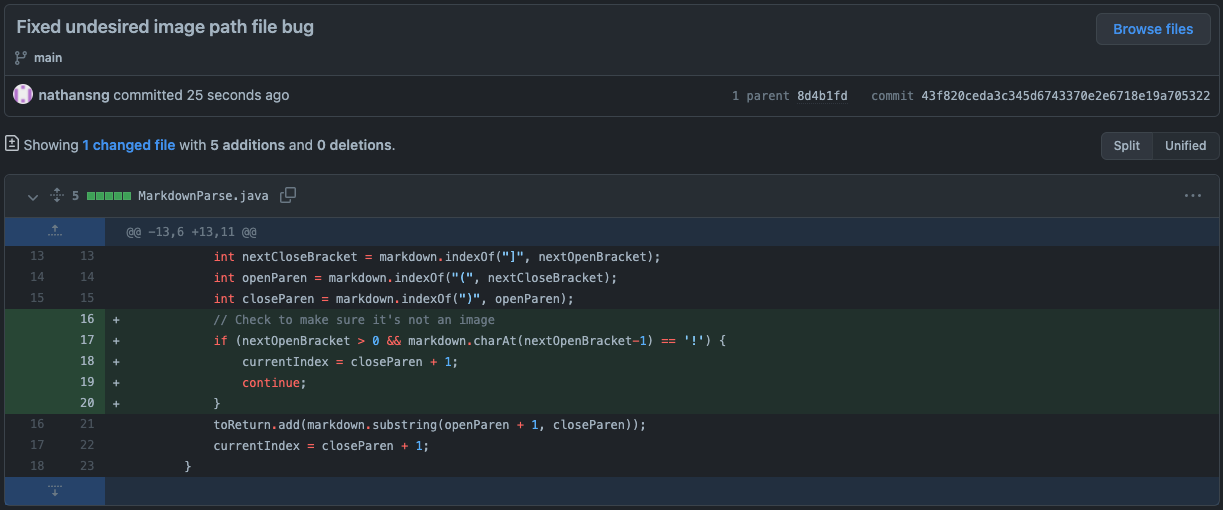
The screenshot above shows the code change I committed to address the symptom and fix the bug. After adding the fix, I ran the program again on the same test file and got the expected output of an empty list because there were no links to extract.

In our first case, the symptom we observed was an incorrect output because it included undesired “links”. The failure-inducing input that resulted in this symptom was a markdown image. The function I used originally didn’t differentiate between markdown images and markdown links and included the file paths of images in the output of links. After looking at the code, I determined that the bug causing this symptom was because there was nothing to check whether it was a markdown image or link. In order to solve this issue, I included code that checked whether there was an exclamation mark before a suppossed markdown link. If there was an exclamation point, then the program would skip the image and move onto the next link.
Case 2: Non-Link Brackets and Parenthesis
The second test case that breaks our function is when brackets and parenthesis are used normally as text in the markdown file. Any text that contains an open bracket followed by a closing bracket, which is then followed by opening parenthesis and then closing parenthesis, will have the text between the parenthesis extracted as a “link”. This was not the expected output of the function because we want the function to work on markdown files that have brackets and parenthesis that aren’t markdown links.
Below is the markdown file that was used as a test that contained brackets and parenthesis that were not intended to be used as links. Link to markdown file
[enter some things in the brackets here] This is just some text
(don't extract this!)
After adding code that fixed the bug in the first case, I ran the function on the new test file and got the following result.

The output extracted the undesired text that was not a link. Any open and closed parenthesis that followed an open and closed bracket resulted in a failure inducing input and returned unintended outputs. This was a symptom of a bug that caused the unwanted results.
Looking back at the code, I discovered that the bug was from the code taking the index of any open parenthesis that came after a closing bracket regardless of where it was in the markdown file. That meant that if I put brackets at the beginning of the file and parenthesis at the end of the file, the function would have considered that as a valid link. To prevent this from happening, I added a checker to ensure that the parenthesis immediately followed the brackets. This way, it prevents unintended text from being extracted because of brackets and parenthesis and limits the function to only extract text from markdown links. Changes to avoid including random text
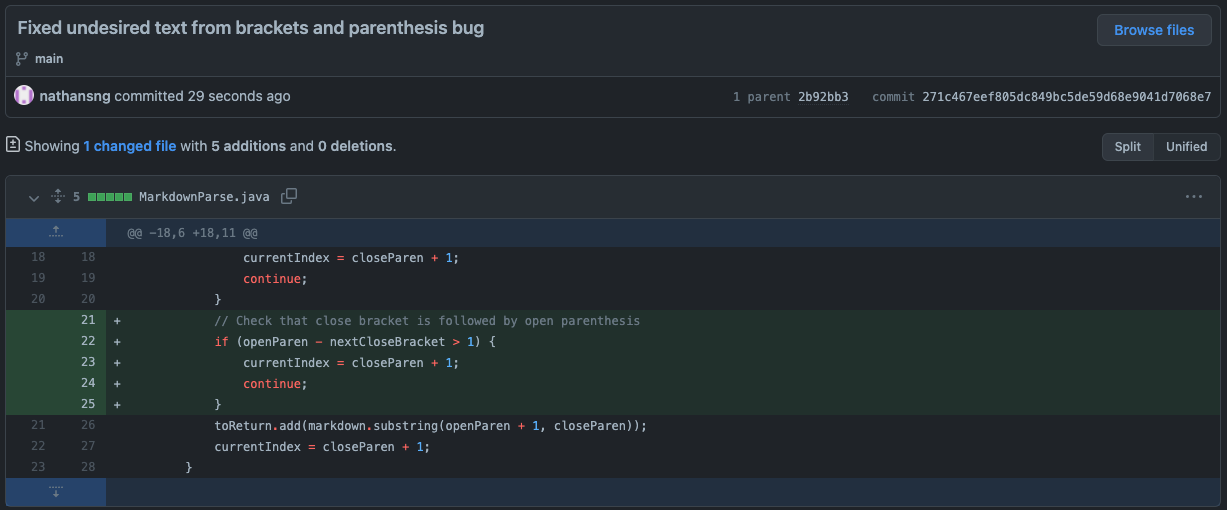
After adding the fix to the bug, I ran the function on the test file again and got the expected output of another empty list.

In the second case of failure inducing input, I observed that brackets followed by parenthesis in the markdown file resulted in including undesired output. The failure-inducing input was any text that used open and close brackets that were followed by open and close parenthesis, regardless of the text in between them. While these were not meant to be markdown links, the function treated them as links and included the text in between the parenthesis in the output, which was the resulting symptom. The bug causing this symptom was no code checking if there was any text in between the brackets and the parenthesis. If there was text in between the brackets and parenthesis, then that meant the it wasn’t a link. To fix the bug, I included a checker to ensure that the parenthesis came immediately after the brackets to avoid extracting unwanted text.
Case 3: Text Beyond Links
The final test case that broke the function was when there was any text that came after the closing parenthesis. If there was a valid or invalid “link” in the markdown file and it was followed by a space, new line, or any text, the program would run for a long time and eventually crash. I wanted the function to avoiding running for a long time and crashing because markdown files can have any number of text after links or parenthesis.
The markdown file underneath was used as the test case that crashed the function to get links. Link to markdown file
[Valid Link](Extract this text here.com)
The link above is valid, but none of this text should be included in the output.
Running the function on this test file resulted in OutOfMemoryError, as seen in the screenshot below.
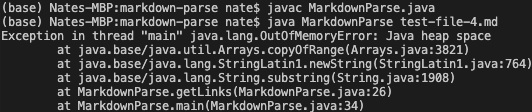
The results of running the function on this test case was very different from the previous two cases. Instead of returning an undesired output, our program ran out of memory and crashed. The out of memory error was a symptom of a bug that caused this output.
In the code, I saw that the reason why the code was crashing was because of how the code extracted the indices of brackets and parenthesis and how the while loop was programmed to stop. In the original function, the while loop in the function would only terminate if the current index was greater than the possible index of the string. However, current index would only be updated by adding one to the index of the closing parenthesis. This meant that the loop would only terminate if the closing parenthesis was the last character in the string, thus causing the current index to be greater than the string length.
Furthermore, the way the function was finding the index of the brackets and parenthesis also contributed to the bug. Java’s indexOf function normally returns -1 if it can’t find the character. Thus, if the closing parenthesis isn’t the last character of the string, the loop would continue and the index of the first opening bracket would be set to -1. Then the function would search for the closing bracket starting from -1, which essentially meant that the function was searching from the start of the string again. This also contributed to the infinite loop and caused current index to never be greater than the string length.
In order to fix this bug, I added a break statement that would break the while loop if it couldn’t find another opening bracket. Once the indexOf returned -1 for the opening bracket, that meant that no more links existed and the function was done extracting. The following is a screenshot of the changes made to the code to accomplish this. Changes to terminate loop
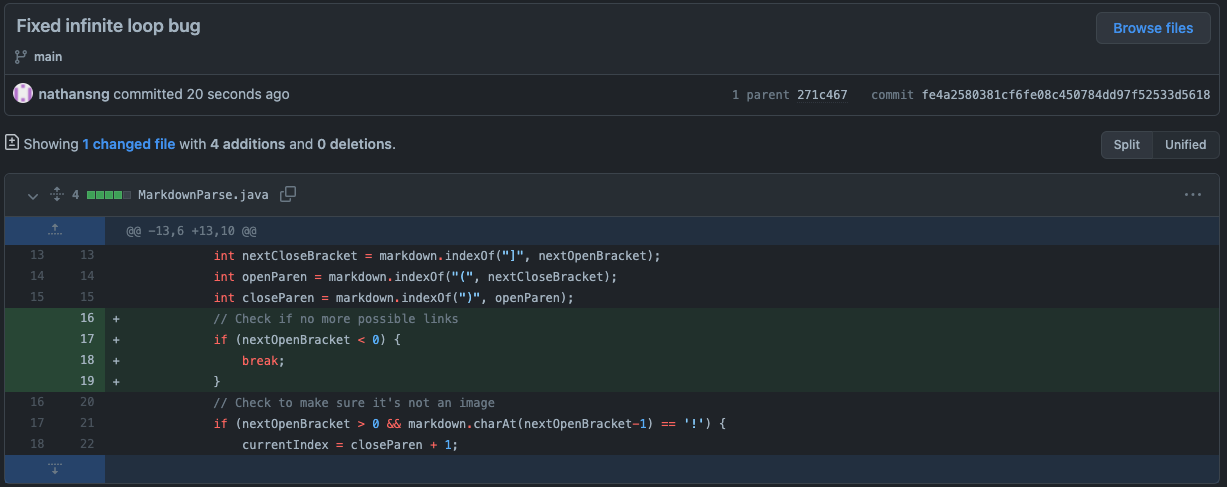
Once I added the break statement, I ran the function again with the test file and got the expected results of a correctly extracted link.

For the third case, I observed that any text following the parenthesis ended up in an infinite loop and an out of memory error. The failure-inducing input that I observed was any text that came after the closing parenthesis, or whenever the closing parenthesis was not the last character of the file. As a result, the symptom was an out of memory error and a long running time before crashing. After looking through the code, I determined that the bug causing this symptom was the way the function terminated the while loop and how the indices were tracked. To address this issue, I included a break statement to end the loop if there were no more opening brackets.
Wrap Up
In this report, I went through the MarkdownParse file and fixed the issues I encountered, whether that was unexpected outputs or errors in the code. While the given function worked on certain test cases, it did not perform as expected for many other test cases, as we saw in the three test cases I fixed. The first test case came from extracting file paths in markdown images, which had a similar format as markdown links. The second test case came from extracting text when using brackets and parenthesis normally in text and not as links. The final test case came from an out of memory error caused by test following the closing parenthesis, or whenver the closing parenthesis was not the last character in the file. For each of these test cases, I created failure-inducing inputs, such as the test markdown files, to reproduce the symptoms. Then I checked the symptoms to see what might be causing the unexpected outcome and the bug in the code. Finally, I looked through the code to find the bug and fixed the issue by adding code that addressed the problem.